Notação Big O - o que é, onde vive, do que se alimenta
Tive uma entrevista hoje e, após quase duas horas de uma boa conversa sobre alguns conceitos-chave de algoritmos e boas práticas de programação, há alguns tópicos que eu gostaria de compartilhar com vocês. Talvez você seja um engenheiro de software experiente e isso possa parecer óbvio para você, mas meu público principal são engenheiros iniciantes e estudantes.
O primeiro tópico sobre o qual gostaria de falar é a Notação Big O. É algo sobre o qual você pode não ter ouvido falar se começou a aprender com cursos online no YouTube (ou mesmo os pagos) que focam apenas em linguagens e frameworks.
Estruturas de dados e algoritmos em geral e outras coisas que as pessoas adoram dizer nas redes sociais que “você nunca vai usar na vida real” são coisas que as pessoas geralmente consideram garantidas.
Sim, você pode nunca usar isso como usa em plataformas como Leetcode, Hackerrank etc. Mas quando você está criando seus próprios algoritmos, esses conceitos estão profundamente relacionados com a qualidade do seu código.
O que é um bom código? Duas coisas:
- Legível
- Escalável
Código legível é um código limpo e claro que outras pessoas possam entender.
Mas neste post estou focando em performance, então estou falando sobre escalabilidade. E aqui é onde o Big O entra.
Código bom
Quando estamos criando um algoritmo para permitir que nossa aplicação faça algo, estamos definindo instruções para que a máquina possa executar o que queremos.
Quando você está fazendo um bolo, você tem muitas maneiras de fazê-lo. As instruções devem funcionar bem com nossa cozinha e ferramentas para que possamos assar o bolo.
E há uma boa maneira e uma maneira ruim de fazer um bolo. Não sou chef, mas sei que podemos fazer uma bagunça em nossa cozinha só para assar um bolo que pode não ser tão saboroso ou bonito.
O uso de ingredientes e ferramentas, a escolha de cada etapa que seguirá a próxima, tudo que você escolhe, terá impacto no resultado final. Talvez você leve mais tempo do que deveria, talvez seu bolo fique horrível, talvez você exploda sua cozinha…
A mesma lógica podemos usar em nosso código. O computador precisa trabalhar com nossas instruções para fornecer algum tipo de resultado. Existem muitas maneiras de dar essas instruções.
Big O e “na minha máquina funciona melhor”
Quando fiz minhas primeiras leituras sobre Big O e como medir a performance do código, insistia em pensar sobre quanto tempo o código levaria para terminar sua execução.
Mas o tempo é relativo. Não quero falar sobre teorias de Einstein. O tempo é relativo porque o tempo que um algoritmo levará para executar depende do poder de processamento da máquina, quantas aplicações estão rodando ao mesmo tempo, qual linguagem de programação é usada, se está rodando em um servidor na nuvem… Muitas variáveis.
As coisas mudaram quando comecei a pensar sobre número de operações.
Digamos que você queira encontrar um item percorrendo um array.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class FindItemInArray {
public static void main(String[] args) {
String[] items = {"apple", "banana", "orange", "grape"};
String target = "orange";
for (int i = 0; i < items.length; i++) {
if (items[i].equals(target)) {
System.out.println("Found " + target + " at index " + i);
}
}
}
}
Se você executar este código na sua máquina, ele rodará em um tempo diferente do meu. E isso é irrelevante. Toda vez que você executar este código será diferente, todos os fatores que mencionei antes impactarão no seu tempo de execução.
O importante é quantos dados temos que lidar e como decidimos lidar com eles.
Existe uma maneira de medirmos o que é código bom e código ruim? À medida que o número de itens no array aumenta, ele ficará cada vez mais lento.
A notação Big O é a “linguagem” que usamos para falar sobre quanto tempo um algoritmo leva para executar. Podemos comparar dois algoritmos para medir qual é melhor que o outro quando se trata de escala.
Como medir?
Não podemos medir em tempo simples. Quando crescemos cada vez mais, quanto o algoritmo desacelera? À medida que um array aumenta de tamanho, quantas operações a mais precisamos fazer para atingir seu objetivo?
A notação Big O descreve o limite superior do desempenho de um algoritmo em relação ao tamanho da entrada. Ela nos permite expressar como os requisitos de tempo de execução ou espaço crescem à medida que o tamanho da entrada aumenta.
Notações Big O comuns incluem:
- O(1): Tempo constante — não muda com o tamanho da entrada.
- O(log n): Tempo logarítmico — cresce lentamente à medida que a entrada aumenta.
- O(n): Tempo linear — cresce diretamente com o tamanho da entrada.
- O(n log n): Tempo linearítmico — comum em algoritmos de ordenação eficientes.
- O(n^2): Tempo quadrático — cresce rapidamente, frequentemente encontrado em loops aninhados.
- O(2^n): Tempo exponencial — cresce muito rapidamente, impraticável para entradas grandes.
Considerando o código que mostrei na última seção, cada fruta que adicionamos ao array, aumentaremos o número de operações acontecendo no loop. Então temos um caso claro de O(n).
O que acontece se tivermos uma função assim?
1
2
3
4
5
6
public class FindItemInArray {
public static void main(String[] args) {
String[] items = {"apple", "banana", "orange", "grape"};
System.out.println("Found " + items[0]);
}
}
O que aconteceria aqui se adicionássemos mais itens?
Estamos sempre pegando o primeiro item. Isso é O(1), o número de operações é 1, não importa quão grande seja o array. É um tempo constante.
Como calcular?
Calcular a notação Big O não requer matemática complexa. Vamos voltar ao primeiro exemplo:
1
2
3
4
5
6
7
8
9
10
11
12
13
public class FindItemInArray {
public static void main(String[] args) {
String[] items = {"apple", "banana", "orange", "grape"}; // O(1)
String target = "orange"; //O(1)
for (int i = 0; i < items.length; i++) { //O(n)
if (items[i].equals(target)) { //O(1)
System.out.println("Found " + target + " at index " + i);
}
}
}
}
Vê os comentários? Considerando cada passo no método, podemos definir notações diferentes. Mas existem regras para tornar nossas vidas mais fáceis:
Pior Caso: Sempre consideramos o pior cenário ao calcular Big O. Isso significa que olhamos para o número máximo de operações que poderiam ocorrer. Quando estamos falando sobre escalabilidade, não podemos assumir que as coisas sempre funcionarão perfeitamente. Por exemplo, no loop, se o item não for encontrado, iteraremos por todos os itens, o que nos dá O(n) no pior caso.
Eliminar Constantes: Ignoramos fatores constantes porque eles não afetam significativamente a taxa de crescimento à medida que o tamanho da entrada aumenta. Por exemplo, O(2n) é simplificado para O(n).
1
2
3
4
5
6
7
8
9
10
11
12
public class FindItemInArray {
public static void main(String[] args) {
String[] items = {"apple", "banana", "orange", "grape"}; // O(1)
String target = "orange"; // O(1)
for (int i = 0; i < items.length; i++) { // O(n)
if (items[i].equals(target)) { // O(1)
System.out.println("Found " + target + " at index " + i);
}
}
}
}
Neste caso, podemos dizer que a complexidade de tempo é O(n) porque o loop itera através de cada item no array, e os fatores constantes (como o número de itens) não mudam a taxa de crescimento geral.
- Termos Diferentes para Entradas:
- Se você tem loops aninhados, você multiplica as complexidades. Por exemplo, se você tem dois loops aninhados, cada um iterando através de n itens, a complexidade é O(n^2).
- Se você tem múltiplas operações independentes, você soma suas complexidades. Por exemplo, se você tem uma operação com O(n) e outra com O(m), a complexidade total é O(n + m).
- Eliminar Termos Não Dominantes:
- Quando você tem múltiplos termos, foque naquele que cresce mais rápido à medida que o tamanho da entrada aumenta. Por exemplo, O(n^2 + n) simplifica para O(n^2) porque n^2 cresce mais rápido que n à medida que n se torna grande.
Considerando essas regras, podemos ter um entendimento claro de como calcular a notação Big O e como aplicá-la em nosso código.
Por que isso importa?
Quando estamos lidando com conjuntos de dados pequenos, o desempenho do nosso código pode não ser um grande problema. Mas à medida que os dados crescem, o desempenho pode se tornar um gargalo. Tendemos a pensar apenas no estado atual. Mas quando estamos construindo aplicações, precisamos pensar no futuro. Como nosso código performará quando os dados crescerem? Como ele escalará?
Quando entendemos a notação Big O, podemos tomar melhores decisões sobre nossos algoritmos e estruturas de dados. Podemos escolher a abordagem certa para o problema em questão, garantindo que nosso código permaneça eficiente e escalável.
Como posso usar isso no meu trabalho diário?
Você pode aplicar a notação Big O no seu trabalho diário:
- Analisando o desempenho dos seus algoritmos e estruturas de dados.
- Identificando potenciais gargalos no seu código.
- Escolhendo os algoritmos e estruturas de dados certos com base em suas complexidades de tempo e espaço.
- Refatorando seu código para melhorar seu desempenho.
Por exemplo, se você descobrir que um determinado algoritmo tem uma complexidade de tempo de O(n^2) e está causando problemas de desempenho, você pode considerar usar um algoritmo mais eficiente com uma complexidade de tempo de O(n log n) ou O(n). Vamos ver no próximo exemplo como podemos melhorar o desempenho do nosso código usando a notação Big O.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.util.HashMap;
public class FindItemInArray {
public static void main(String[] args) {
String[] items = {"apple", "banana", "orange", "grape"};
String target = "orange";
// Using a HashMap to improve performance
HashMap<String, Integer> itemMap = new HashMap<>();
for (int i = 0; i < items.length; i++) {
itemMap.put(items[i], i);
}
Integer index = itemMap.get(target);
if (index != null) {
System.out.println("Found " + target + " at index " + index);
} else {
System.out.println(target + " not found");
}
}
}
Neste exemplo, usamos um HashMap para armazenar os itens e seus índices. Isso nos permite alcançar complexidade de tempo O(1) para buscas, melhorando significativamente o desempenho em comparação com a complexidade O(n) da busca linear anterior.
Como você pode ver na imagem abaixo, é uma boa referência para ter em mente quando você está pensando sobre performance e escalabilidade do seu código. 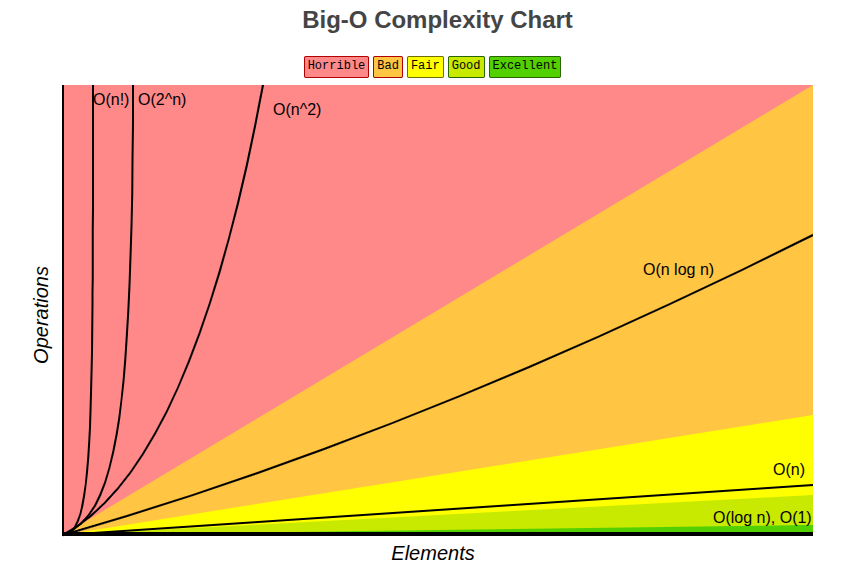
Recapitulação da Notação Big O
A notação Big O é uma maneira de descrever o desempenho de um algoritmo em termos de sua complexidade de tempo e espaço. Ela nos ajuda a entender como um algoritmo escalará com tamanhos crescentes de entrada e nos permite comparar diferentes algoritmos com base em sua eficiência.
É essencial para escrever código eficiente e escalável, especialmente ao lidar com grandes conjuntos de dados ou algoritmos complexos. Ao entender a notação Big O, podemos tomar decisões informadas sobre os algoritmos e estruturas de dados que usamos em nossas aplicações.
Neste post não estou falando sobre uso de memória, este é um tópico para outro post. Mas é importante notar que a notação Big O também pode ser aplicada à complexidade de espaço, que se refere à quantidade de memória que um algoritmo usa à medida que o tamanho da entrada aumenta.
Este post faz parte das coisas que gosto de compartilhar quando estou estudando ou aprendendo algo novo. Tento manter simples e claro, para que você possa entender os conceitos sem se perder em jargões técnicos. Se você tiver alguma pergunta ou sugestão para tópicos futuros, sinta-se à vontade para entrar em contato!
Comments powered by Disqus.